Difference between revisions of "Phylogenetics: R Primer"
(→Plotting the density function) |
|||
| Line 85: | Line 85: | ||
The type is specified to be a lower case L character here (L for line). For other plot types, see the online help by typing: | The type is specified to be a lower case L character here (L for line). For other plot types, see the online help by typing: | ||
help(plot) | help(plot) | ||
| + | |||
| + | === Modifying a plot === | ||
| + | R does a fairly nice job of selecting defaults for plots, but I find myself wanting to tweak things. This section explains how to modify various aspects of plots. | ||
| + | ==== Line width ==== | ||
| + | To make the line connecting the points thicker, use the <tt>lwd</tt> option (<tt>lwd=1</tt> is the default line width): | ||
| + | plot(x,y,type="l",lwd=3) | ||
Revision as of 00:05, 16 March 2009

|
EEB 349: Phylogenetics |
| This lab represents an introduction to the R computing language, which will be useful for upcoming homework assignments as well as for software written as R extensions (i.e. APE) |
Contents
What is R?

While R and Python share many similarities, R excels in tasks that involve statistics and creating plots. While a spreadsheet program like Excel can create charts, it is often easier to create the plot you need in R. The purpose of this lab is to introduce you to R by showing you how to make various plots related to probability distributions. This will also enable you to learn about several important probability distributions that serve as prior distributions in Bayesian phylogenetics.
Installing R
Install the R package by going to http://www.r-project.org/ and following the download instructions for your platform.
Gamma distribution
As an introduction to R, let's use it to explore the gamma distribution. The gamma distribution has two parameters that govern its shape and scale. Here are some basic facts about gamma distribuitons:
| Shape parameter | 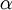
|
| Scale parameter | 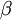
|
| Mean | 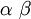
|
| Variance | 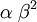
|
| Density function | 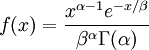
|
Note that that 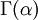 in the density function refers to the gamma function (which is distinct from the gamma distribution). The gamma function is easy to calculate when its argument is a positive integer:
in the density function refers to the gamma function (which is distinct from the gamma distribution). The gamma function is easy to calculate when its argument is a positive integer:
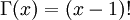
When, however, the argument is an arbitrary positive real number (which is the usual situation for ), then computing it gets more complicated. Fortunately, R handles details like this for us!
When the gamma distribution is used to model rate heterogeneity in phylogenetics, its mean is set to 1 because it is being used to model relative rates. In this application, only the shape parameter is ever specified, and that is because the scale parameter is determined by the constraint that the mean is 1.0.
if is known and the mean must be 1.0?Creating a Histogram
Let's begin by drawing 1000 random numbers (deviates) from a gamma distribution (shape=0.5, scale=2.0) and creating a histogram. Type the following command into the R console to generate the random deviates and store them in the variable x:
x = rgamma(1000, shape=0.5, scale=2.0)
The "r" in "rgamma" stands for "random". There is an "r*" command for all the common probability distributions (e.g. rbeta, rbinom, rchisq, rexp, rnorm, runif) and in each case it allows you to draw a sample of values from that distribution (e.g. the beta, binomial, chi-square, exponential, normal and uniform distributions, respectively).
It may appear that nothing has happened, but you can view the 1000 values stored in the variable x by typing x at the prompt.
Creating a basic histogram from these 1000 values is easy:
hist(x)
Now refine the histogram by telling R that you want there to be 50 bars:
hist(x, breaks=50)
Plotting the density function
The "d*" commands (e.g. dgamma, dbeta, dexp, dnorm, dunif) can be used to compute the probability density function for a series of values. In this part of the tutorial, you will use the dgamma function to compute the gamma density function for all 501 values in the series 0.0, 0.01, 0.02, ..., 5.0. First, generate the values in the series and store in a variable named x:
x = seq(0.0, 5.0, 0.01)
The seq generates a series of values starting at the first supplied value (0.0 in this case), stopping at the second supplied value (5.0 in this case), with spacing between values in the sequence determined by the third supplied value (0.01 in this case). To see if 501 values were generated, type
length(x)
You can list all the values in x by simply typing x at the console.
R makes it easy to compute a quantity for every number in a list. Here is how to compute the gamma density function value at each value stored in the variable x:
y = dgamma(x, shape=10, scale=0.01)
Before plotting the density function, you should convince yourself that R is computing the density correctly by doing one value yourself by hand. First print out the 100th x value as follows:
x[101]
(Note that indexes begin at 0 in R (as in most programming languages), so the first value is x[0], the second is x[1], and so forth. That's why the 100th value has index 101.) The value displayed should be 1.
=10 and = 0.1Compare your value to the value computed by R:
y[101]
Now plot the density function as follows:
plot(x,y)
This command says to plot all possible pairs of points, where one value is taken from x and the other from y. There are 501 values in both x and y, so 501 points will be plotted. This plot looks kindof ugly with lots of overlapping points. More reasonable would be to connect the points with a line but not to print all 501 points themselves. You can do this by adding type="l" to your plot command:
plot(x,y,type="l")
The type is specified to be a lower case L character here (L for line). For other plot types, see the online help by typing:
help(plot)
Modifying a plot
R does a fairly nice job of selecting defaults for plots, but I find myself wanting to tweak things. This section explains how to modify various aspects of plots.
Line width
To make the line connecting the points thicker, use the lwd option (lwd=1 is the default line width):
plot(x,y,type="l",lwd=3)